
Support for Large Language Models
Heureka’s proprietary indexing and classification platform enables rapid visibility into and access to data necessary for enterprise large language models (LLMs).
LLMs and unstructured data will power enterprise AI. However, collecting data to build and train LLMs is challenging. Specifically, the ability to search vast volumes of unstructured data efficiently is problematic.
Each day, structured data is converted to unstructured data outside the secure perimeter. Unstructured data contains IP, operational and strategic data.
– Retrieve data from endpoints to feed large language models
– Operationalize daily retrieval from thousands of endpoints based on defined criteria
– Classify endpoint data and drive API’s to automatically update LLM
– Pre-processing filters out Redundant, Obsolete and Trivial data
– Index & classify unstructured data in the wild: endpoints, file shares & cloud storage
– Scalable to support thousands of endpoints and large file shares – anywhere in the world
ID and classify for large language models.
Everyday. Everywhere.
Evolving privacy laws, complex litigation, and increased focus on data governance makes real-time data access and intelligence even more important.
%
Of Organizational Data Is Unstructured.
%
Estimated Annual Growth of Unstructured Data.
%
Of Data is ROT. (Redundant, Obsolete or Trivial)
Average Savings of Having Centralized Data Compliance.
%
Of companies don’t know where their sensitive data resides.
Extra E-Discovery Processing and Collection Fees
Real-Time Tools To Easily Manage Your Data.
Computers and file shares are overflowing with critical and sensitive data such as national identification numbers, credit cards information or intellectual property.
Heureka’s automated tools help you :
Proactively Mitigate Risk
Quantify risk exposure and increase business resiliency by finding and eliminating data with no business, legal or regulatory value.
Ensure Governance and Compliance
Regularly audit governance and compliance policies to measure effectiveness.

Reduce Litigation Costs
Search and analyze data at the point of creation while collecting only the information necessary to your case.
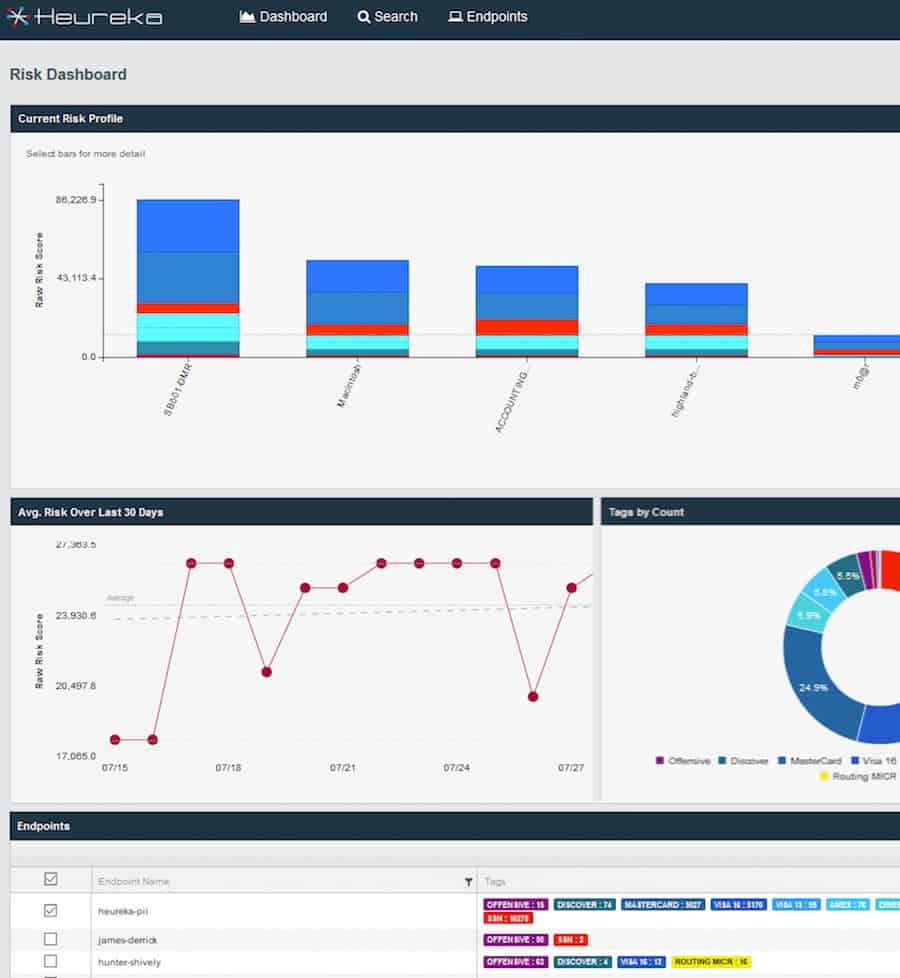
Our Solutions
The Heureka Intelligence Platform makes it fast and easy to search and manage your data across your entire enterprise.

GDPR
Respond to Subject Access Requests by finding and identifying subject identities across your endpoints.

E-Discovery
Search and analyze data at the point of creation allowing you to surgically target and collect only the most relevant data to reduce time and processing costs.

Governance & Compliance
Enforce document retention policies and eliminate ROT. Automatically classify sensitive data to meet regulatory & compliance requirements.
Our Clients Are Awesome
Our clients tell us everyday how much they love the Heureka Intelligence Platform. The reason is simple, we provide results!




Frequently Asked Questions
What operating systems does Heureka support?
Heureka supports Microsoft® Windows® 7+, MacOS® 10.5+ and multiple versions of Linux®.
Do you support file shares?
Absolutely! Heureka works across multiple file shares with options to improve performance when the share sizes get really big.
Does local endpoint indexing slow my system down?
No, Heureka was built from the ground-up with user performance in mind. We have specific endpoint tuning to help throttle and govern the amount of resources the indexer uses when running. Most users will never even know we are there.
Is all indexed information centralized back to a server or appliance?
Absolutely not! All Heureka indexes remain local on each endpoint. We do not duplicate custodian information to search or analyze it. File metadata-only is transferred to the Heureka Command Console when identified via a search.
Does Heureka require extra software licenses such as SQL or Microsoft Office?
No, Heureka uses the opensource PostgreSQL database to hold search query information. No extra licenses are required.