
City Government Case Study
Client Background:
The city has approximately 30,000 residents and has been recognized by Money in its list of “Best Places to Live” multiple times. Some other recognition includes:
- Rated as one of the safest in their state
- Highly rated public school system
- Ranked as one of the “best places to raise kids” by Bloomberg Businessweek.
- Granted Google eCity award multiple times recognizing them as the city with the strongest online business community their state.
Their Challenge:
Their main concern was the risk associated with unidentified PII data in unstructured data, spread across their file shares and endpoints.
Reasons
Lack of visibility about what PII information existed across the organization in unstructured data.
No cohesive system to cover both file share and individual endpoints.
No ability to remediate file risk with quarantine and delete functions.
Difficulty thoroughly responding to FOIA requests across unstructured data.
What They Needed
A Cloud-based system to ensure security and allow for rapid, same-day deployment.
Ability to quantify risk exposure by finding and eliminating data with no business, legal or regulatory value.
A system that would work with all of their technology platforms such as Windows, Linux, OSX, etc.
Single interface to search, analyze, and take action across all their deployed endpoints that would be easy-to-use for non-technical users.
The Solution:
Heureka’s team assisted the city in conducting a Proof of Concept (POC) in mounting 10 different share points consisting of just over 600 GB of data. This POC included, but was not limited to, the following:
A cloud-based system and UI – Allows for rapid deployment (less than 2 minutes) and the ability to proactively manage endpoints, PII risk, view risk trends, create reports, conduct searches or take file action.
Platform agnostic file share and endpoint agents – Our low-impact indexing agents run locally on all platforms including Windows, Mac, Linux, and file shares without an OS. Each system silently creates a full text and metadata index, in the background, and then updates daily with new or modified information with zero impact on machine performance.
Heureka’s automatic classification engine – Our engine identifies specific PII such as social security numbers, credit card numbers and bank routing information.

Rapid Assessment:
Get In less than 24 hours, Heureka’s indexing and classification engine ran and recorded 725,000 files with 643 GB of total size. Upon completion of the index and classification, the Heureka team created a data assessment report based on common file types and presented the report to the client. The data assessment search requires less than three minutes to complete and returns files that are automatically tagged by Heureka’s classification engine.
Within minutes, The Heureka Platform identified their highest data risk was due to social security numbers, bank routing numbers, and Visa card numbers hidden in their unstructured data.
Risk Identified From Unstructured Data
Files Scanned, Indexed and Classified
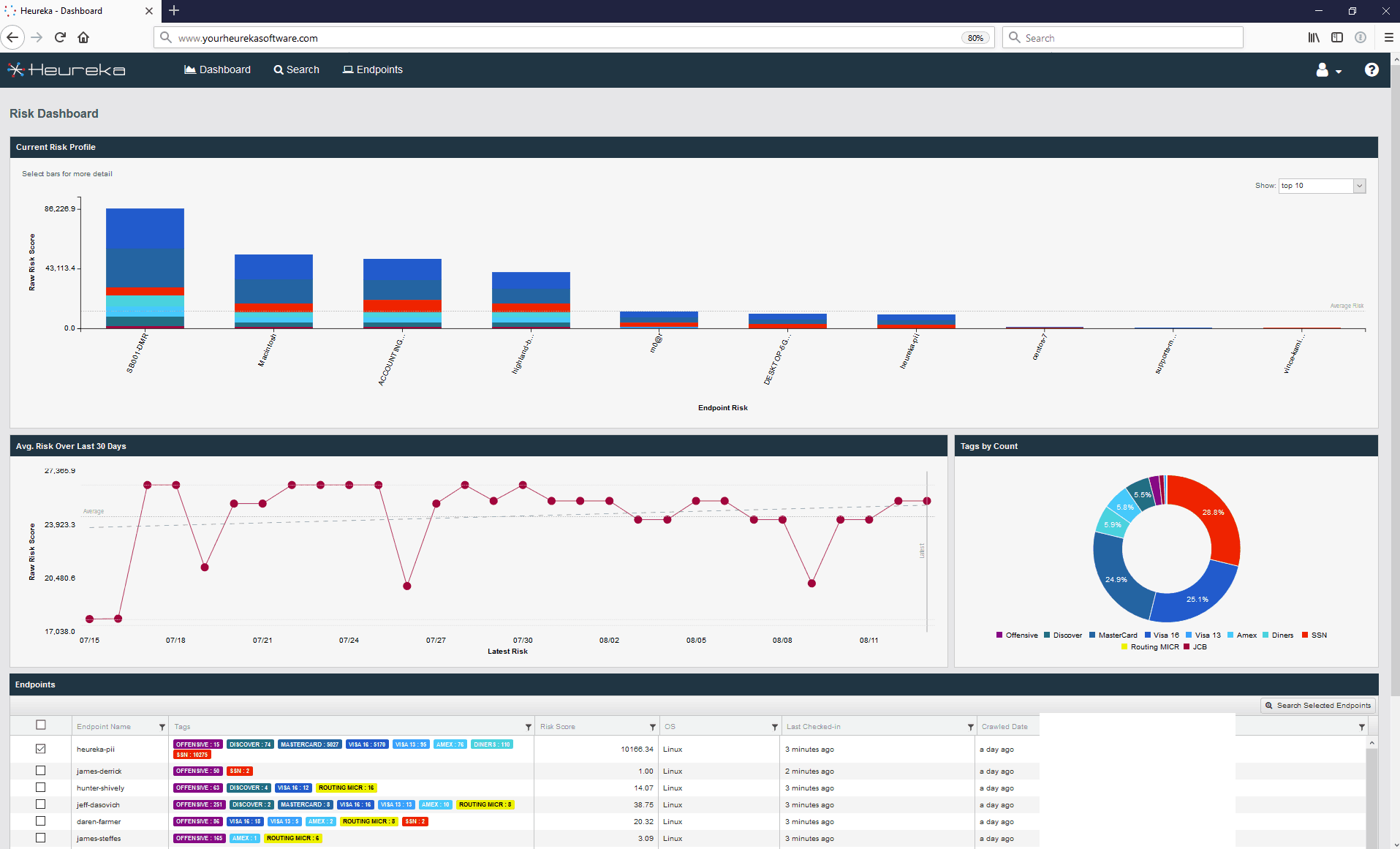
Sorting the data by year and risk score yields interesting results and clearly points toward a potential data retention issue. In this case, the greatest amount of potential risk occurred in files from 2010 and 2014. The strength of Heureka’s platform is not only the ability to rapidly identify and classify information but to provide tools to remediate (quarantine or delete) files on any endpoint including file shares.
Conclusion:
In less than two days, Heureka helped our client identify over $578,000 worth of potential risk. More importantly, files falling outside of typical data retention policies were quickly identified. Heureka returns valuable file information such as the file name, hash value (file fingerprint) and more importantly for our client, the full file path inside the file share. Users may search file content in the same rapid manner as the risk tag information by using keywords, Boolean queries, hash values or combinations for reduced false positives.
Heureka is now working with the client to remediate their risk as well as potentially expanding Heureka’s footprint to additional file shares as well as endpoint computers.
Heureka is fast and flexible to deploy, highly configurable and can be either cloud-based or deployed on-premises. Our indexing engine can be tuned up or down depending on data sets, hardware or VM capability. Risk is auto-classified by Heureka’s engine or can be customized by the user with custom regular expressions.