
Classify Unstructured Data: Why, How & What

Why Classify Unstructured Data
The main reason to classify unstructured data is to achieve Data Privacy compliance. We are singularly focused on keeping sensitive data safe – away from bad actors – for the sake of our employees, stakeholders and customers.
Unmanaged. Untethered. Unsecured.
Classifying unstructured data is paramount post-pandemic. Unstructured data comprises 80% of all data, is home to PII, and represents a large attack surface for cyberthieves:
Market observers agree that data quality – specifically, unstructured data quality – is paramount:
- 86% acknowledge vulnerability to security threats, 34% as “very” or “extremely” vulnerable
- 57% of Chief Data Officers estimate the cost of data quality doubled in the past 3 years
- 45% say unstructured data is focus of data-driven initiatives
- 45% agree sensitive data discovery/classification is a ‘Top 3’ initiative
eWEEK’s “Data Points” article stresses the importance of data classification (click eWeek graphic for story):
- Regulatory Readiness
- Faster Data Searches
- Improved Security Controls
- Email Protection
- Classification-based File Storage
- Retention Policy Enforcement
How to Classify Unstructured Data
Damian Alderson’s article, 5 Data Classification Best Practices to Improve Your Business Workflow, provides pragmatic direction.
“The way your business will classify, label and manage data, both critical and less important, depends on myriad factors” including (click image to read article):

- Type of data
- Pertinence of data
- Level of accessibility
- Security clearance
- Sensitivity
Damian suggests these best practices:
- Determine the Location of Your Data
- Use “Value” as the Main Classification Factor
- Identify Your Most Sensitive Data
- Valid Retention Policy
- Ensure Consistency and Proper Maintenance
What…
to avoid
Traditional classification tools often lack granular data information and leave ‘classification‘ decisions in the hands of the users. Those decisions vary from user to user and often fail to comply with governance guidelines. And some classification tools lack sophistication, such as:

- No propagation to other document copies on the network
- Cannot tag common file types like .txt or .csv
- Neither import classification libraries from other systems nor export classification tags to other systems, i.e., DLP
to anticipate
Most everyone agrees that data privacy compliance benefits all and data classification is the work necessary to be compliant. Improved outcomes include:
- Regulatory Readiness – Improve litigation responsiveness and quickly respond to Subject Access Requests (DSAR’s)
- Improved security controls – classifying data improves all other security controls – encryption, identity and access management (IAM) and data loss prevention (DLP)
- Email protection – assign sensitivity levels to unstructured files
- Classification-based file storage – added protections levels
- Retention policy enforcement
- Fewer data records impacted by 63%
- Reduced system downtime by 32%
- Brand loyalty, customer trust, corporate citizenship, and shorter sales cycles by 37%
- Avoid punitive damages
We Can Help
The journey to compliance requires exacting processes. Heureka’s Advanced Classification & Tagging (TM) engine is granular classification of sensitive data, insight that informs other data-driven workflows, such as DLP/cyber, data compliance, data privacy and GRC. Benefits include:
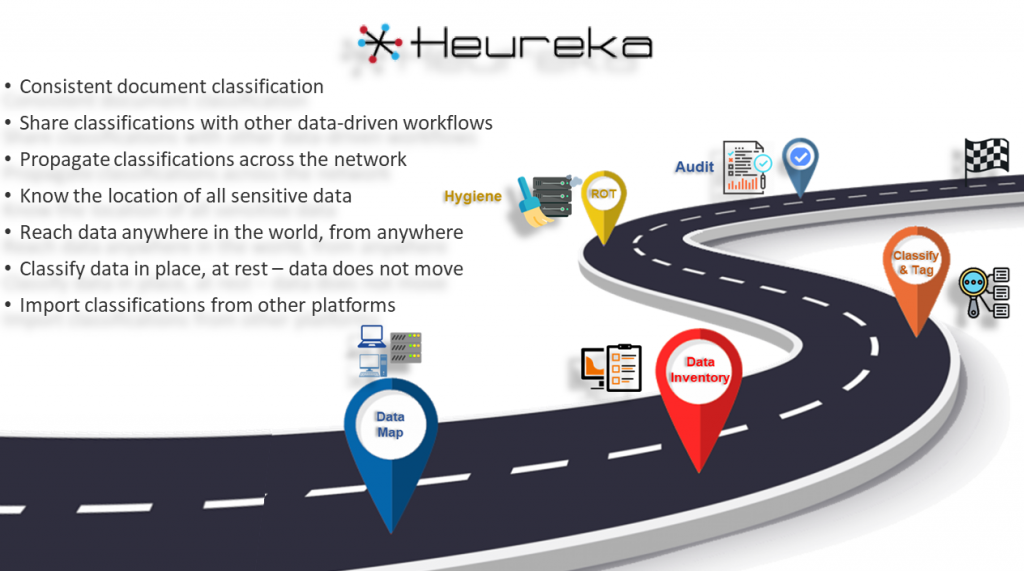
Schedule a demo to find out more.
More information about Heureka’s Advanced Classification & Tagging can be by found clicking the image below.