
Data Classification: Why Classify Unstructured Data

Data classification is particularly necessary for unstructured data. Unstructured data comprises 80% of all data: it’s unmanaged, untethered, and unsecured. eWEEK’s “Data Points” article stresses the following:
- Regulatory Readiness
- Faster Data Searches
- Improved Security Controls
- Email Protection
- Classification-based File Storage
- Retention Policy Enforcement
Read the full article here: (https://www.eweek.com/development/eweek-data-points-six-reasons-to-classify-unstructured-data/)
And to that list, we add the following reasons for classifying unstructured data:
- Defensible Data
- Protecting sensitive data from cybersecurity threats
- Improved response for litigation preparation & investigations
Challenges for Data Governance/Privacy Professionals
Traditional classification tools often lack granular data information and leave ‘classification’ decisions in the hands of the users, and those decisions vary from user to user. And some classification tools lack sophistication: .
- No propagation to other document copies on the network
- Cannot tag common file types like .txt or .csv
- Neither import classification libraries from other systems nor export classification tags to other systems, i.e., DLP
Rapid Data Visibility & Management
Heureka’s ACT engine mitigates traditional classification shortcomings with visibility to identify and govern critical and sensitive data across the enterprise. The process is centralized and users immediately see when sensitive data is at risk. The heart of Heureka ACT is the Central Classification Library. All document classification tags load to the central repository and propagate to all copies in the enterprise.
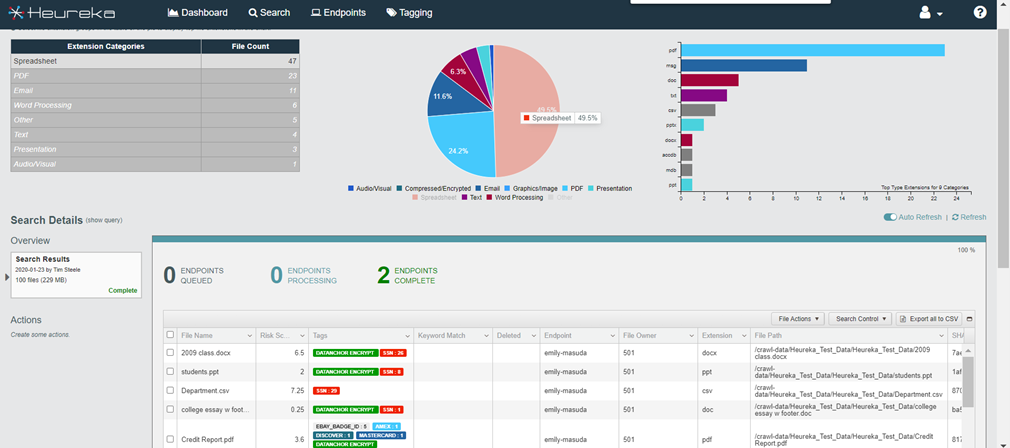
Granular Control
Granular classification tags identify specific critical and sensitive data. Tags are accessed by way of the Tagging API and used in other data driven platforms. Heureka’s compliance dashboard displays high-risk endpoints along with the risk types including PII information. Current and 30-day views are instantly available along with user selectable drill-down.
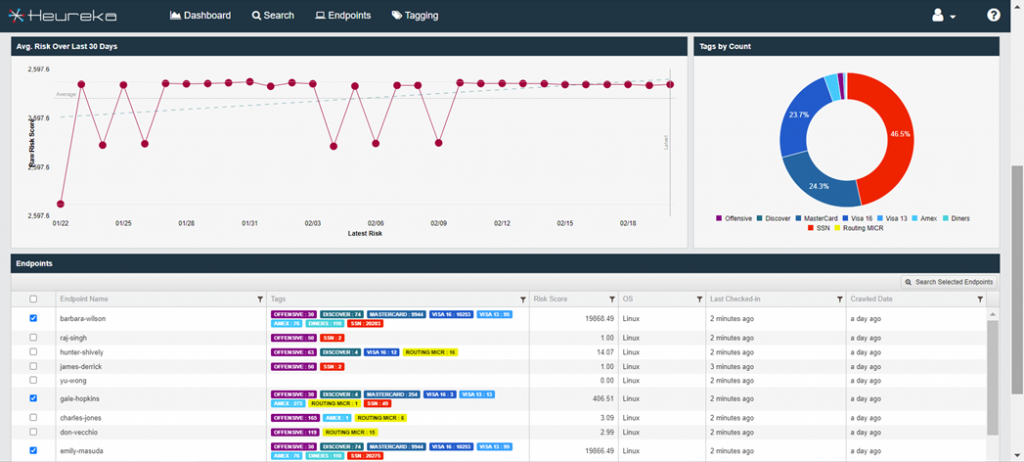
Select endpoints for file-level searching including Boolean, metadata and regular expressions. File-level actions such as collect, quarantine or delete round out the workflow along with export reporting.
- Single user interface manages all endpoints
- Map and track sensitive data in real-time
- Analyze data in-place without copying
- Find documents with Boolean regular expression searching
- Collect, quarantine or delete from the console
- Auto-classification and scheduled searching
- Robust RESTful API
Benefits of Heureka ACT
- Central library provides consistent document classification
- Propagate classification decisions duplicate files across the network
- Always know the location of critical and sensitive
- Respond to privacy and cybersecurity events quickly and easily
- Share classification tags with other data driven workflows
- Import classification & tagging decisions from other platforms
Why Wait?
- Pushing data to the edge increases the attack surface – 39% of companies are aggressively disrupting markets and 65% of those have been breached.
- Data breaches outpace the increase in cyber security budgets by 200%+
- Cyber security models and best practices do not account for ‘borderless’ data.
- 86% acknowledge vulnerability to security threats, 34% as “very” or “extremely” vulnerable
- 57% of Chief Data Officers estimate the cost of data quality doubled in the past 3 years
- 45% say unstructured data is focus of data-driven initiatives
- 45% agree sensitive data discovery/classification is a ‘Top 3’ initiative