
Gain control over your data life cycle
There’s no denying the growing importance of data. Data is becoming the differentiator for companies that are commanding markets of choice and especially deep knowledge of stored, unstructured data. Knowledge, after all, can and will be used as a competitive advantage for years to come.
With corporate data ballooning by 63% per year, organizations should have policies in place to manage it all—and it begins with understanding the life cycle of data, from discovery to remediation.
Heureka has created a handy graphic to help visualize the life cycle around data and its associated risk.
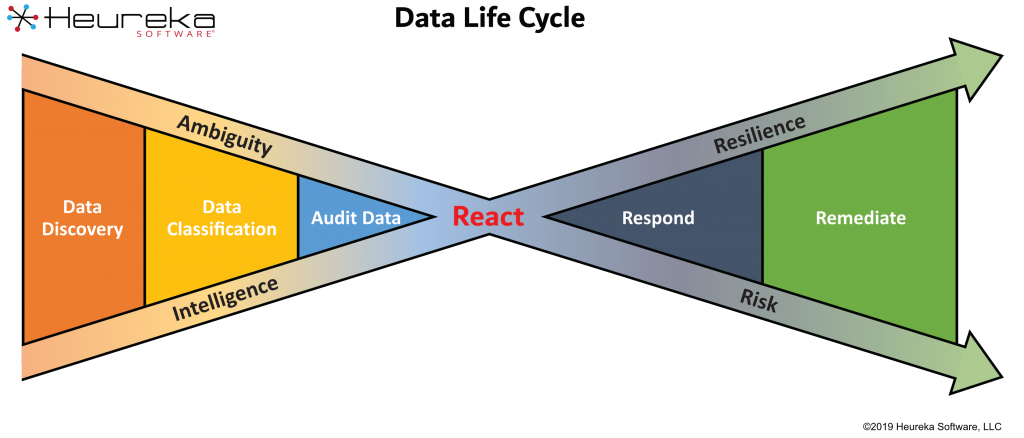
The data life cycle includes the following steps:
- Data Discovery: When data flows into an organization, whether through data entry, acquisition, from an external source or a signal reception.
- Data Classification: Determine the type of data and where it is located, simplifying retrieval and tagging for search.
- Audit Data: Assess the purpose or usefulness of data (including that which already existed).
- React: Put it to use.
- Respond: Evaluate the effectiveness.
- Remediate: Delete unnecessary data once its useful life is over.
Unstructured Data Life Cycle
Phase One – Start point (far left): A typical data life cycle begins with nearly zero intelligence and a high level of ambiguity about data. In this phase, data has built up over time on servers, laptops, desktops and in the cloud.
Phase Two – Data Discovery, Classification and Audits
Phase two of the data life cycle begins when a company implements tools to discover, classify and audit their information. Ambiguity around the data immediately begins to drop as intelligence is gained. This phase naturally leads toward a reaction.
Phase Three – React, Respond, Remediate
Phase three starts the process of reacting to the data intelligence a company has gained on their information. As companies respond and remediate their data, their resilience dramatically increases as their risk decreases. Deep content knowledge and classification of information quickly pivots toward policy generation, security and cyber-security implementation and ultimately remediation of data no longer needed because it is considered ROT or risky data that is now understood and controlled.
In addition to detailing the steps of the data life cycle, the Heureka graphic shows how your organization’s grasp of the data will evolve over time.
Notice the intersecting arrows in the graphic: The more data intelligence you have, the more resilience you have (and thus the upward-facing arrow). At the same time, as you increase intelligence you are naturally reducing ambiguity. When ambiguity is eliminated, so too is risk (and thus the downward-facing arrow). The point at which the paths of intelligence and ambiguity cross paths is the point of reaction, when intelligence around your data is put to use.
How Heureka Helps
The data life cycle sounds straightforward, right? Surprisingly, it hasn’t always been easy to manage because the tools to index and classify information efficiently and cost effectively were lacking.
Heureka was developed to specifically address the growing need to gain control of and insight into critical, unstructured data that is often of little value — but houses risk – and to improve upon the economics of a resource-intensive process to manage that data. Heureka provides the tools to manage the complete process, from discovery to remediation.
The automated Heureka Intelligence Platform starts by locating and classifying unstructured data (learn more about the power of classification here, and see the article about our upcoming presentation on the topic at PREX).
Once an endpoint is installed, a full text and metadata index is silently created in the background and is updated daily with new or modified information. All classification tags applied to documents in place are uploaded to the central library and then shared to other machines running Heureka. Heureka’s automated classification engine also performs a daily sweep for PII information such as national identity, credit card numbers and bank routing information. Heureka’s risk dashboard provides a unique Heureka risk score and gives users a current and thirty-day historical view providing at-a-glance risk trends across an enterprise.
It’s important to remember that massive amounts of data are hiding within organizations and serving no business value. Making matters worse, the data that is actually important is at risk of getting lost in the shuffle. (Learn about the power of remediation in our recent article on the topic)
Visit HeurekaSoftware.com for more information.